
人在环路的机器人在线可持续示教学习
2021-09-22 01:00:04胡艳明
无人系统技术 2021年4期
胡艳明,华 炜
(之江实验室,杭州 311121)
1 引 言
机器人在现代社会与经济的发展中扮演着重要的角色,显著地提高了人类的工作效率与安全性,并加快了科学发展的进程。与人类相比,现有的机器人在未知环境下的行为能力还很低下[1-3]。参照人类提升行为能力的方式,研究人员通过研究基于示教学习的机器人学习方法,使机器人通过模仿示教者来获得新的行为。
示教学习是通过最小化机器人与示教者之间的行为差异来获得新行为的技术[4]。相比基于“试错”的强化学习,示教学习的样本使用率与学习效率更高。但是,示教学习依赖示教样本的质量,所学行为鲁棒性较差,较小误差的动作会使机器人逐渐偏移正确的行为,从而在真实应用中失效。针对该问题,研究人员提出一系列经典算法,如基于搜索的结构化预测算法[5]、随机混合迭代学习算法[6]、数据集聚合(Dataset Aggregation, DAgger)算法[7-8]、基于示教的近似策略迭代算法[9]、用于模仿的聚合值算法(Aggregate Values to Imitate, AggreVaTe)[10]等(详细介绍见文献[11])。随着生成对抗网络(Generative Adversarial Network, GAN)[12]的提出,许多研究人员利用GAN 的样本生成能力,提出了基于GAN 的模仿学习算法,如生成对抗模仿学习[13]、互信息生成对抗模仿学习[14]、多智能体对抗模仿学习[15]、奖励增广模仿学习[16]、基于动作排序的对抗模仿学习[17]等。
以上所示的大部分经典算法与基于GAN 的算法由两个基本时期组成:①示教样本收集;②策略导出。对于示教学习来说,示教样本包含了机器人可能学到的行为。当机器人遇到示教样本中未包含的场景时,所学行为极有可能会失效。这类填鸭式的示教学习方法使机器人不具备适应新环境的能力。为了能够适应新遇到的场景,经典算法中的DAgger 与AggreVaTe 采用数据增广技术在线收集更多专家的示教数据。但是,该类方法需要专家一直处于关注状态,且需要时刻给机器人提供观察状态对应的示教动作。因此,DAgger 与AggreVaTe 的学习成本高昂。此外,以上方法都是其于深度学习的方法[18]。但是,深度学习会出现灾难性遗忘问题[19-20],即学习的新行为会覆盖之前所习得的行为,深度学习的灾难性遗忘问题至今没有得到很好的解决。DAgger与AggreVaTe 方法会在接收到新样本后,将其混入数据集中一起对模型进行重训练,学习效率很难进一步提高,进而限制了环境适应性与行为鲁棒性的提升。综上所述,当前的示教学习方法主要存在三方面的问题:①环境适应性差;②学习效率低;③行为鲁棒性差。
基于径向基函数(Radial Basis Function, RBF)网络的增量式学习方法被应用于可持续强化学习任务中[21-22]。本文融合该增量式学习方法与示教学习,将人类加入到机器人学习的环路中,使机器人能够在遇到新场景时主动向人类请求示教;并仅利用新接收的新数据增量式地学习行为,使机器人能不断适应新环境。其次,为了降低人在环路的示教学习的交互成本,利用传统优化方法[23]将人类易示教的高层行为转换成机器人易学习的低层行为。再次,借鉴大脑基底神经节中纹状边缘区域的工作机理[24-25],赋予机器人潜意识学习的能力,使其能够在内部世界不断产生虚拟的数据用于学习,进一步得到鲁棒的行为。最后,通过移动机器人学习走廊通行行为实验证明了本文方法是合理有效的。
2 人在环路的可持续示教学习框架
本文提出如图1 所示的人在环路的可持续示教学习框架。该框架由三部分组成:①基于增量式RBF 网络的可持续示教学习;②基于贝塞尔曲线的轨迹跟踪;③机器人潜意识学习。可持续示教学习使机器人能够主动与外部世界进行交互——请求人类示教或在真实世界中利用学到的行为。因此,人类被加入到机器人学习的环路中,并在机器人的整个生命周期对其进行示教引导。轨迹跟踪方法将高层级的参考轨迹转换成低层级的状态-动作对。基于此,人类仅需要给机器人提供能够拟合成参考轨迹的稀疏引导点。潜意识学习通过在内部世界对新场景进行探索,生成多样性的示教数据,使机器人学到更加鲁棒的行为。下面将分别对这三部分进行详细介绍。

图1 人在环路的机器人可持续示教学习框架Fig.1 Human-in-the-loop continual robot learning from demonstration framework
2.1 可持续示教学习
示教学习(Learning from Demonstration, LfD)归属于有监督学习范畴。在监督学习中,学习系统被有标签的数据训练,并学习近似该数据分布的函数。在示教学习中,训练数据由示教者执行任务的示例组成。最终用于示教学习的示例是一个二元组<x,a>,它由状态及动作组成。示教学习的目的是学习一个策略π:x→a。现有的大部分示教学习方法都是一次性的学习,即机器人基于固定的示教数据集学习,策略会在学习完成后固定下来,机器人可能无法适应新出现的场景与情况。本节通过融合示教学习与基于RBF网络的增量式学习,提出可持续示教学习算法。
文献[22]提出基于RBF 网络的增量式学习方法。图2 显示了一个标准的RBF 网络模型,其由模型参数W与结构D={d1,d2,…,dn}两部分组成。L2 正则化的核递归最小二乘(L2-norm Kernel Recursive Least Squares, L2-KRLS)算法被用来增量式学习RBF 网络的参数与结构(详见文献[22]的算法1)。其中,近似线性独立(Approximate Linear Dependence, ALD)准则用来判定状态是否需要加入D。具体地,对于第t个遇到的状态xt,计算xt被D近似线性表示的误差δt,如果δ t>μ则将该状态加入D,其中μ为设定的阈值。ALD准则如式(1)所示:
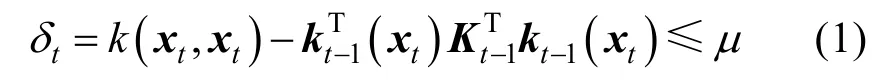
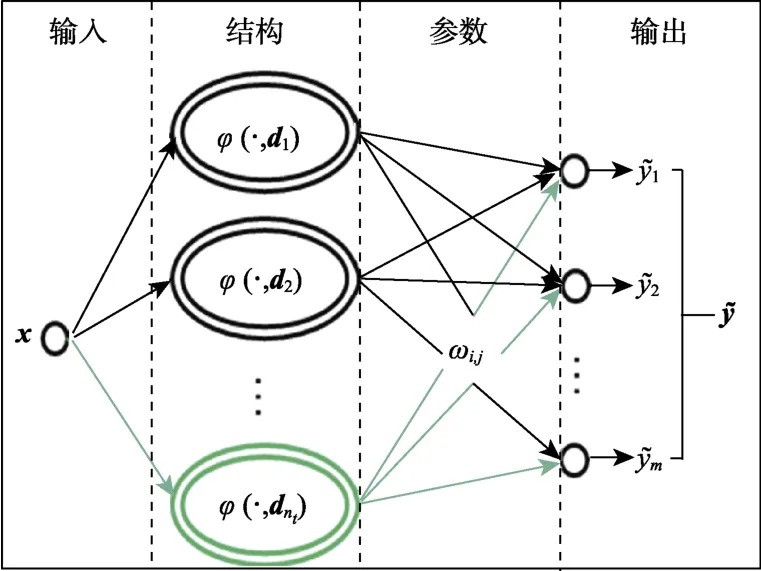
图2 增量式RBF 网络Fig.2 Incremental RBF network
本文利用ALD 准则作为机器人与人类主动交互的机制。对于机器人的每一个决策周期,可分以下三种情形。
情形1:如果机器人已经获取到期望的执行动作at,则利用<xt,at>输入到L2-KRLS 算法对RBF 网络进行更新。
情形2:如果机器人此时未获得期望的执行动作at,并且xt满足ALD 准则(δt≤μ),则利用所学的RBF 网络生成当前状态的可执行动作at。
情形3:如果机器人此时未获得期望的执行动作at,并且xt不满足ALD 准则(δ t>μ),则向人类发出请求示教信号获得执行动作at,并利用<xt,at>输入到L2-KRLS 算法对RBF 网络进行更新。
2.2 基于贝塞尔曲线的轨迹跟踪
为了使机器人能够利用人类示教的高层行为示教数据学习,本节提出基于贝塞尔曲线的轨迹跟踪算法将参考轨迹转换成状态-动作对。当人类接受机器人的示教请求信号时,便向机器人提供当前场景的稀疏引导点,假定提供五个引导点,可表示为R={(x1,y1) ,(x2,y2) ,… ,(x5,y5)}。利用式(2)所示的三次多项式对引导点进行拟合,得到机器人的参考路径S。
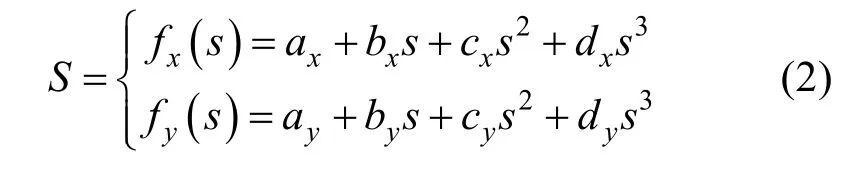
轨迹跟踪方法规划出最优的动作使机器人跟踪上该参考路径。机器人在对参考路径进行跟踪的过程中会生成状态-动作对,并基于此对RBF网络模型进行更新。
本文提出的轨迹跟踪算法是文献[23]中基于贝塞尔曲线的离散优化框架。首先,利用贝塞尔曲线公式生成候选轨迹;然后,利用设计的评价函数对每条候选轨迹进行评价;最后,选出代价最低的作为当前的最优执行轨迹。
候选轨迹生成:本文以移动机器人Turtlebot[22]为实验对象,采用二阶贝塞尔曲线模拟机器人的行驶轨迹。二阶贝塞尔曲线由三个控制点唯一确定。假定候选轨迹的个数为NPT,第i条候选轨迹可表为图3 为候选轨迹各控制点的选择示意图。图中所有点均在机器人本体坐标系XOY下,X轴为机器人正前方。候选轨迹的第一个控制点为机器人坐标系原点;第二个控制点为机器人正前方γPTLPT处的点;候选轨迹最后一个控制点是在[-φPT,φPT]区间的圆弧上进行均匀采样获得。其中,γPT是控制轨迹平滑程度的因子;为圆弧上的角度采样间隔。各控制点的计算公式见式(3)。
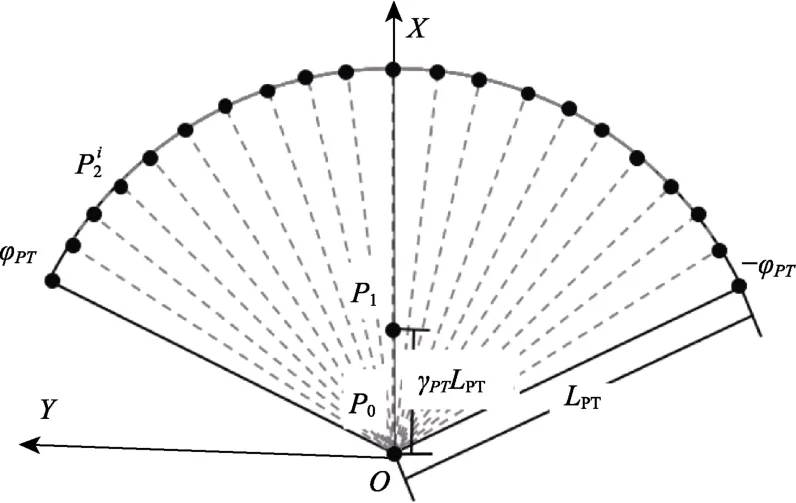
图3 候选轨迹控制点采样示意图Fig.3 Control points of candidate trajectories
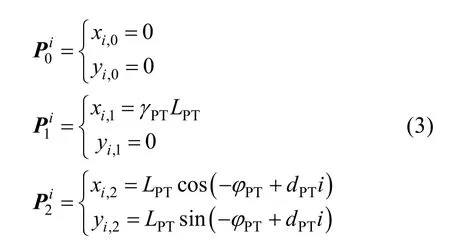
评价函数设计:本文采用候选轨迹与参考路径的重合度作为评价指标。第i条候选轨迹的代价计算公式如下:
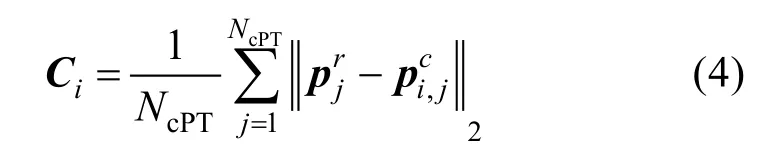
其中,NcPT为一条曲线上均匀采样点的个数;为参考路径上第j个采样点;为第i条候选轨迹上第j个采样点;采样点p是由二维平面上坐标值组成的二维向量[x,y]。
最优轨迹选择:根据设计的评价函数得到各候选轨迹的代价值后,选择代价最小的轨迹作为当前的执行轨迹。图4 给出轨迹跟踪方法的示例。图中,粉红色点表示人类给出的示教路点,红色 曲线为拟合的参考路径,黄色曲线为生成的候选轨迹簇,绿色曲线为最终选定的最优执行轨迹。
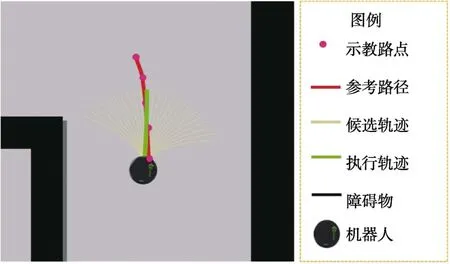
图4 轨迹跟踪方法示例Fig.4 Example of bézier curve based path tracking
得到最优可执行轨迹后,可以计算机器人的执行指令。Turtlebot 的执行指令为速度(v)和角速度(ω)。由于Turtlebot 的移动速度相对缓慢,可以固定为常值不变,角速度成为唯一影响轨迹跟踪的指令。根据公式(5)计算最优候选贝塞尔曲线起点处的曲率k0,再根据ω=vk计算当前机器人期望的执行角速度。最后,利用传感器数据构造机器人当前的状态xt,并结合机器人的期望动作at=[ω]组成用于行为学习的示教样本

2.3 潜意识学习
为了进一步提高机器人学习的效率,借鉴大脑的工作机制,赋予机器人潜意识学习的能力。所谓的潜意识学习即机器人在内部世界对外部世界遇到的新场景进行探索,生成多样性的训练样本,用于更新行为模型。潜意识学习使得机器人不必暂停与外部世界的正常交互,它利用内部世界产生的多样性虚拟样本提升机器人在真实世界的行为能力。本文将潜意识学习分成三个子问题:内外世界计算资源配置、内部世界与外部世界的数据流控制以及如何在内部世界探索新场景。
计算资源配置:本文框架按计算资源解耦可得三个独立的模块:内部世界探索、外部世界交互、行为可持续学习。这三个模块可以进行并行计算,并且三个模块之间的计算允许异步进行。因此,根据不同的情况,存在如图5 所示的三种配置情况:(1)在相对简单的任务时,如果机器人配置的计算资源充足,甚至配备多台计算的情况下,三个模块可以都放于本地;(2)如果任务复杂,存在大量的内部世界片段需要被探索,可将内部世界模块置于云端计算,缓减本地计算的压力,同时这也是一种降低机器人硬件成本的途径;(3)如果任务的复杂性再增加,可以将增量式学习与内部世界模块都置于云端计算,这种方式需要以合适的频率更新机器人本地的策略模型。
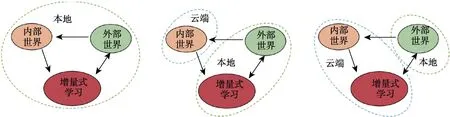
图5 计算资源配置Fig.5 Allocation of computing resources
数据流控制:机器人本体在真实世界中运行以及与人类交互的同时,系统的内部世界也在并行运行着。内部世界中,机器人需要采样各种初始姿态以完成对虚拟环境的充分学习。外部世界不定时地会出现需要请求人类示教的场景。可能会出现这种情况:上一个虚拟环境还未被内部世界利用完成,就接收到新的虚拟环境。针对该情况,有两种应对策略:(1)虚拟环境队列,记为E,如图6 所示;(2)内部世界列表,记为I,如图7所示。前者只需要维持一个内部世界,待处理的虚拟环境被暂存在队列中,按先进先出的顺序依次输入到内部世界被学习。后者是存在多个并行处理器(或多个机算机)的前提下,新到来的虚拟环境被随机分配到当前空闲的处理器/计算机,此处的每个处理器/计算机就是机器人各个内部世界的载体。
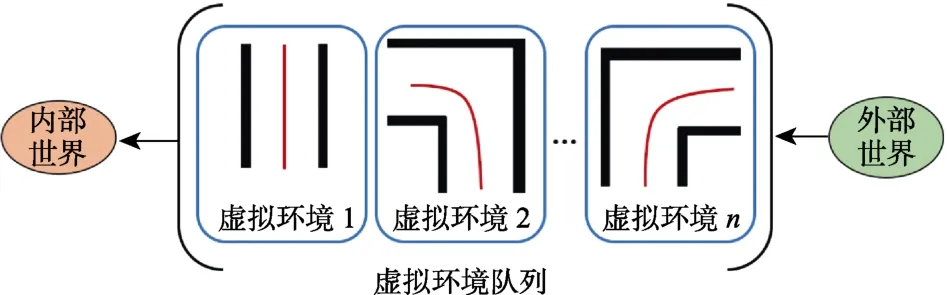
图6 虚拟环境队列Fig.6 Virtual environment queue
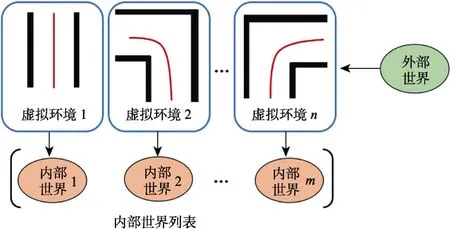
图7 内部世界列表 Fig.7 Internal world list
新场景探索:潜意识学习的核心思想就是在不干扰机器人在外部世界运行的前提下,利用内部世界对陌生的环境进行系统的学习,使机器人学到更加鲁棒的行为。为了达到该目的,机器人在内部模拟时,需要获得多样化的样本。机器人以某一初始姿态跟踪上参考轨迹,这一过程可作为一个场景。机器人需要在同一虚拟环境模拟足够多的初始姿态,从而完成对该局部环境的探索。图8 给出一个在内部世界探索左转角场景的例子。首先,从参考轨迹(粉红色曲线)上采样一系带方向的点(青色箭头)作为虚拟参考初始位姿点;然后,对各虚拟参考初始位姿点按式(6)添加确定扰动,分别得到左、右两个探索初始位姿点。
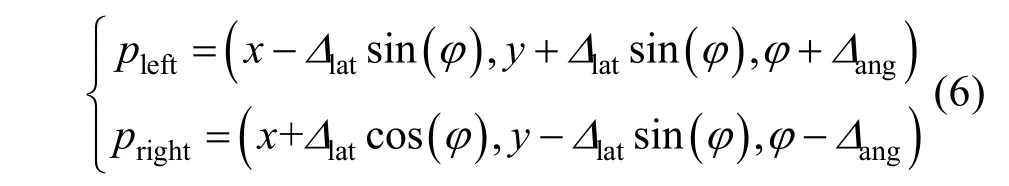
其中,Δlat为横向扰动量,Δang为角度扰动量。
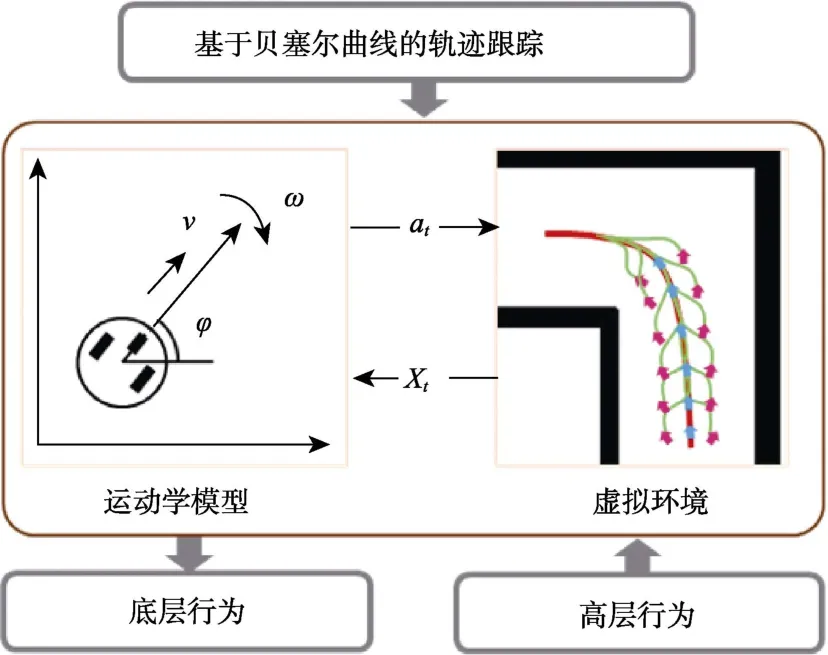
图8 内部世界探索新场景示例Fig.8 Example of exploring new scene in internal world
在确定计算资源的配置与数据流控制方案后,根据内部世界探索新场景的方法获得若干探索初始位姿点。对于每个探索初始位姿点都构建一个用于探索的虚拟场景实例。在虚拟场景实例中利用基于贝塞尔曲线的路径跟踪方法获得最优执行动作,利用运动学模型更新下一步的状态,这样迭代若干周期得到一系列用于行为学习的虚拟状态-动作对。
3 人在环路的可持续学习系统
由第2 节介绍的人在环路的可持续学习框架,可实例化人在环路的可持续学习系统。该系统由三个并行运行的线程组成,分别为:(1)外部世界线程;(2)内部世界线程;(3)增量式学习线程。图9 给出三个线程之间的数据交互关系图。共享队列变量QH与QL分别存储高层行为与低层行为,它们在三个线程间共享。外部世界推进新的高层行为,并将当前得到的低层行为推进QL。内部世界线程接收从QH中推出的高层行为,并将得到的低层行为推进QL。增量式学习线程接受QL推出的低层行为增量式更新策略模型。得到的策略模型在增量式学习线程与外部世界线程间共享。下面分别对三个线程进行介绍。
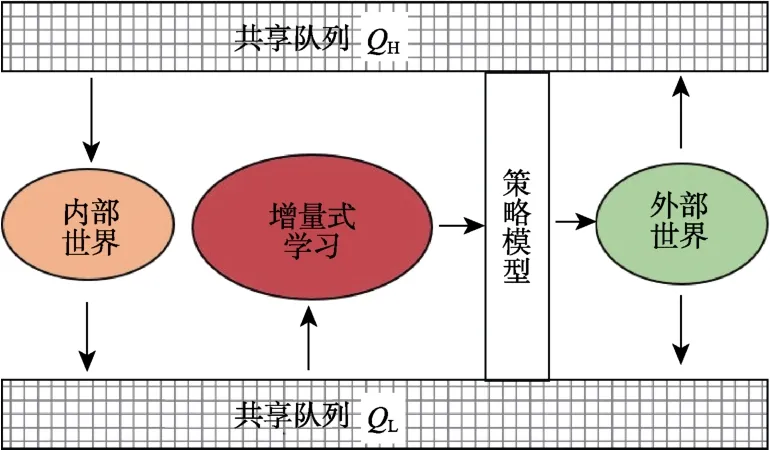
图9 各线程之间的数据流Fig.9 Data stream between each threads
3.1 外部世界线程
外部世界线程主要负责机器人与真实世界的交互,包括获取环境的信息、自身的状态、与人 类进行交互以及执行动作作用于环境。该线程基于增量式学习线程学习到的策略模型信息判定当前机器人是否需要请求示教,因此,存在两种状态:(1)利用学习到的行为;(2)请求示教获得行为。如果为前者,则利用学习到的策略模型生成当前期望动作;否则调用轨迹跟踪方法得到当前的期望动作。在每一个运行步,机器人都要发布期望动作到底层控制器,对环境作出响应。外部世界线程具体步骤如下。
步骤 1:初始化srobot←利用,t← 1;
步骤 2:使用传感器获得机器人当前的状态xt与位姿rt;
步骤 3:如果srobot==利用,执行步骤 4;否则,执行步骤 5;
步骤 4:如果xt满足ALD 准则,则利用RBF网络输出当前状态的期望动作at;否则,从人类示教者获取引导点R,并利用式(2)拟合参考路径S,然后将S存入高层行为队列QH末尾,置srobot←示教;跳至步骤 6;
步骤 5:如果轨迹未跟踪结束,则基于轨迹跟踪方法获得执行动作at,并将(x t,at)存入低层行为队列QL末尾;否则,srobot←利用;
步骤 6:将期望动作at发布给底层控制器执行,t←t+ 1,跳转至步骤 2。
3.2 内部世界线程
内部世界线程主要负责从共享队列QH中获取虚拟环境,构成内部世界,从而模拟得到低层的行为,并存储到共享队列QL。线程中主要分为两个部分:(1)对机器人的初始位姿进行采样,得到一系列虚拟实例,并存入队列Qtemp;(2)从队列Qtemp中获取虚拟实例,并调用轨迹跟踪方法得到低层行为。内部世界线程具体步骤如下。
步骤 1:t← 1,Qtemp←∅;
步骤 2:如果Qtemp==∅并且﹁QH==∅,弹出,并获取QH队首的参考路径S,并在S采样若干探索初始位姿{r1,r2,…},依次构造(S,ri),i=1,2,…存入Qtemp;弹出,并获取Qtemp队首单元(S,r),赋值Snow←S,rnow←r;
步骤 3:如果Snow跟踪未结束,则基于Snow与rnow,用轨迹跟踪方法获得at,获取虚拟状态xt,将虚拟状态动作对(x t,at)存入低层行为队列QL末尾,基于机器人运动学模型更新rnow;否则,弹出,并获取Qtemp队首单元(S,r),赋值Snow←S,rnow←r;
步骤 4:t←t+ 1,跳转至步骤 2。
3.3 增量式学习线程
增量式学习线程的任务相对简洁,它只负责从QL获取训练样本,增量式地更新机器人的策略网络。当队列为空时,便暂停学习;当队列有数据时,便开启学习。增量式学习线程具体步骤如下。
步骤 1:t← 1;
步骤 2:如果﹁QL==∅,则弹出,并获取QL队首的状态-动作对x,a),并利用(x,a)增量式更新RBF 网络;
步骤 3:t←t+ 1,跳转至步骤 2。
4 实验结果及分析
4.1 仿真环境实验
本实验基于移动机器人平台Turtlebot[26]与基于ROS[27]与Stage[28]的回形仿真走廊环境验证人在环路的可持续示教学习方法的有效性。机器人需要在搭建的回形走廊仿真环境中,通过与人类的交互,逐步学习通道行驶行为。本实验包括三组实验。
(1)人直接示教低层行为,不包含轨迹跟踪与潜意识学习模块,简称为simpleLfD;具体地,机器人主动地向人类请求示教;然后,人类利用游戏手柄直接给出期望动作控制机器人运行一段距离,并产生一系列状态-动作对(x,a);同时用在线产生的(x,a)增量式更新行为模型。
(2)人示教高层行为,包含轨迹跟踪模块,但不包含潜意识学习模块,简称为BZPTLfD;具体地,机器人主动地向人类请求示教,然后,人类通过点击地图界面给机器人提供五个稀疏引导点,紧接着拟合得到参考路径,然后基于轨迹跟踪算法跟踪该路径一段距离,产生一系列状态-动作对(x,a),同时用在线产生的(x,a)增量式更新行为模型。
(3)本文完整框架;具体地,机器人主动向人类请求示教,然后,人类通过点击地图界面给机器人提供五个稀疏引导点,紧接着拟合得到参考路径,然后基于轨迹跟踪算法跟踪该路径一段距离并收集一系列状态-动作对存入低层行为队列QL,同时,潜意识学习对新场景进行探索获得一系列状态-动作对也存入QL,增量式学习依次从QL中取(x,a)更新行为模型。
图10 显示了最终的实验结果。图中绿色曲线为机器人依靠所学策略行驶的轨迹,红色箭头记录了每次机器人请求示教时的位姿。如果机器人能够仅依赖学习到策略完整运行一圈,期间没有出现需要请求示教的状态,就说明机器人对该环境学习完成。三种方式下,机器人依靠人类的示教增量式地更新策略模型,最终都能够利用所学行为在该回形走廊环境中正常行驶。图10(a)为simpleLfD 的结果,机器人总共向人类请求了53次示教;图10(b)为BZPTLfD 的结果,人类示教23 次;图10(c)为本文完整框架,所需示教次为13 次。仔细观察图10 中,三张图中记录的示教位姿分布以及学习完成后的行驶轨迹。
图10(a)显示simpleLfD 在走廊拐角处的红色箭头与绿色轨线存在许多不一致的情况,这说明机器人在学习过程中,由于人类很难直接控制机器人按照期望的轨迹运动,因此机器人所学行为不断变化。BZPTLfD(图10(b))与完整框架(图10(c))的红色箭头与绿色轨线基本重合,即示教轨迹与所学行为基本一致。这说明基于贝塞尔曲线的轨迹规划方法将人类更加易于给出的高层稀疏路点转换成更加稳定的机器人行为,提高行为学习的稳定性。simpleLfD 与BZPTLfD 在走廊拐角处存在许多重叠或相近的示教位姿(重叠的红色箭头),这种红色箭头重叠现象在本文完整框架(图10(c))中明显减少。这说明,当机器人不具备潜意识学习能力时,遇到历史场景时会陷入故障状态,需要重复向人类请求示教;然而,使机器人在内部世界对新场景进行探索的潜意识学习能够提高行为学习的鲁棒性与效率。
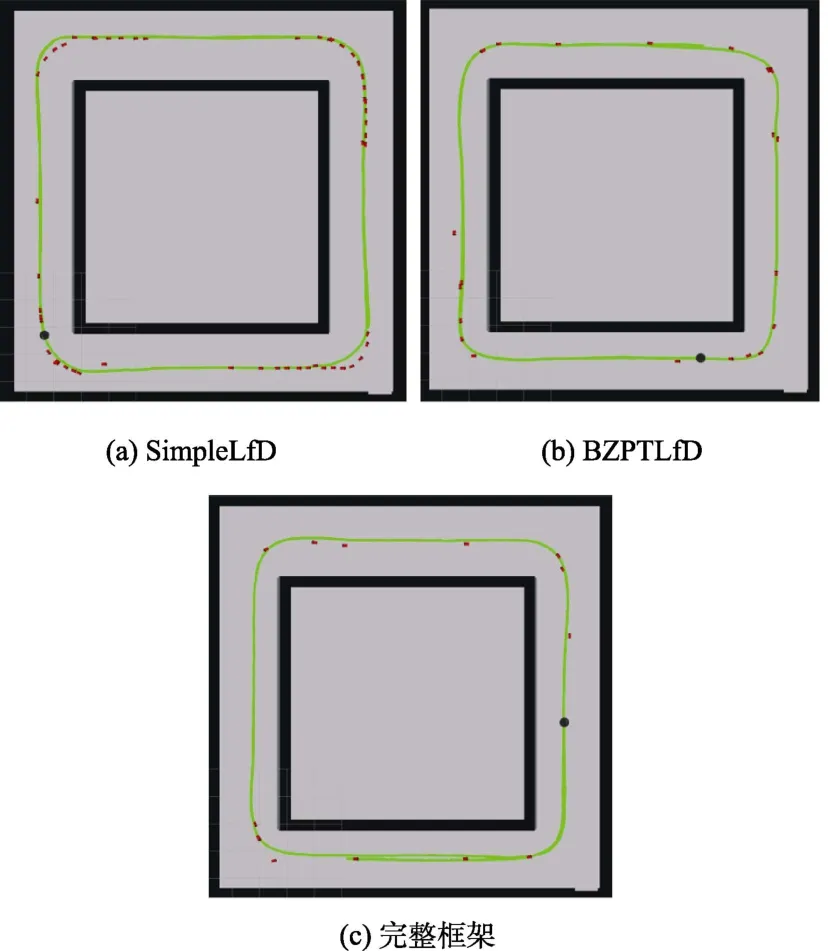
图10 仿真实验结果。Fig.10 Experiment results in virtual environment
实验结果表明:(1)融合增量式学习方法与示教学习方法,将人类加入到机器人学习的闭环中,的确能够使机器人自主地向人类请求示教,并且能够增量式地学习不同的行为;(2)将传统规划(轨迹跟踪)方法与机器人学习方法结合,使人类仅需要向机器人提供高层的行为,降低了人类交互的成本,并提高了机器人学习的效率与稳定性;(3)具有潜意识学习能力的机器人,可在内部世界中进行模拟,生成大量虚拟的样本,进一步提高机器人学习的效率,并提高了所学行为的鲁棒性。
4.2 真实环境实验
为了验证本文方法在真实环境中的有效性,本节在真实环境中搭建了如图11 中间所示的回字形走廊环境。Turtlebot 被随机置于该环境中某位置,然后基于本文提出的人在环路的机器人在线可持续学习框架主动向人类请求示教,基于示教数据在线可持续地学习走廊通行行为。

图11 真实环境实验结果Fig.11 Experiment results in real environment
图11 中周围一圈实景图片显示了机器人在对应时间的状态,红色时间表示请求示教,白色表示自主运行。最后,机器人只向人类请求了5次示教,便学会了在该走廊通道正常行驶的行为。图12(a)显示了该实验,RBF 网络的神经元个 数随着学习的进行,在线增长的情况;图12(b)显示了随着学习的进行,机器人请求示教的频次(次/秒)。结果显示,随着学习的进行,RBF 网络的节点个数从零开始增加,学习也能够快速收敛。
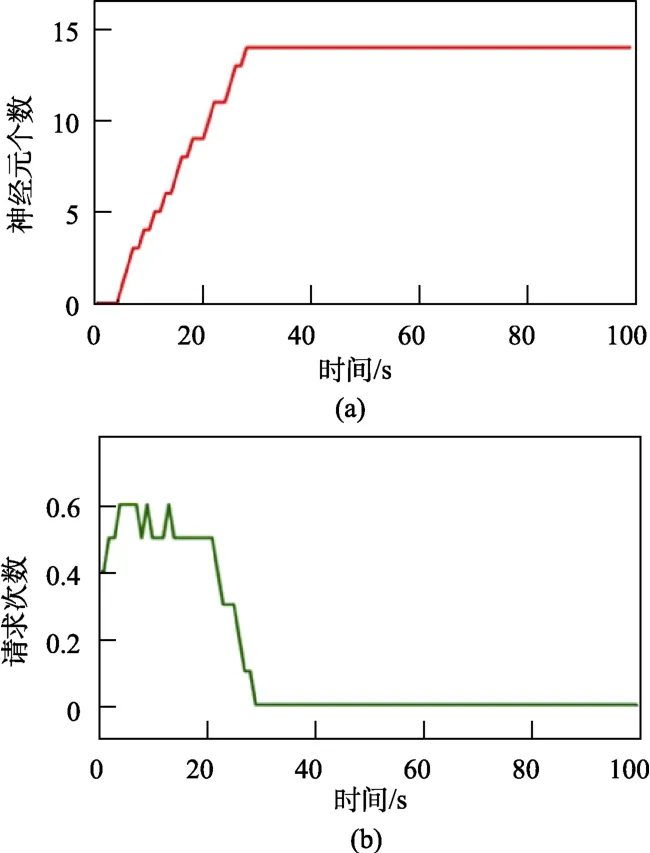
图12 仿真实验结果Fig.12 Experiment results in simulation
5 结 论
本文融合基于RBF 网络的增量式学习方法与示教学习方法,提出人在环路的增量式学习方法。为了降低人类交互的成本以及人类示教的不确定性,将传统规划方法加入机器人学习方法中,使人类只需要向机器人提供高层的行为(路点或路径)。然后,利用基于贝塞尔曲线的路径跟踪方法将人类示教的高层行为转换为机器人的可执行动作(低层行为)。低层行为可以直接被机器人学习到策略模型中。另外,赋予机器人潜意识学习的能力,使其在内部世界不断模拟出虚拟数据,丰富机器人的知识储备,从而提高所学行为的鲁棒性。综合各模块,得到最终的人在环路的在线可持续学习系统。本文通过回形走廊环境的通道行驶行为学习实验验证了人在环路的增量式学习框架的有效性。实验结果表明:人在环路的增量式学习方法能够以使机器人通过与人类的主动交互,高效率、增量式地学习到鲁棒的行为。同时,真实环境中的回形走廊实验验证了本文方法在真实应用中的有效性。
猜你喜欢
当代陕西(2022年6期)2022-04-19 12:12:22
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
中学生数理化·中考版(2019年9期)2019-11-25 09:39:44
现代装饰(2018年5期)2018-05-26 09:09:39
中国三峡(2017年2期)2017-06-09 08:15:29
环球市场(2017年36期)2017-03-09 15:48:21
电信科学(2016年9期)2016-06-15 20:27:25
电子设计工程(2015年16期)2015-02-27 12:07:58
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
