
融合用户评分和属性相似度的协同过滤推荐算法
2017-04-24 10:40:37王三虎王丰锦
计算机应用与软件 2017年4期
王三虎 王丰锦
1(吕梁学院计算机科学与技术系 山西 吕梁 033000)2(同方股份有限公司 北京 100083)
融合用户评分和属性相似度的协同过滤推荐算法
王三虎1王丰锦2
1(吕梁学院计算机科学与技术系 山西 吕梁 033000)2(同方股份有限公司 北京 100083)
为了提高协同过滤推荐系统的推荐效率和准确性,更好地向用户提供个性化的推荐服务,提出一种用户评分和属性相似度的推荐算法。首先分析当前协同过滤推荐研究的现状,设计相似度、兴趣倾向相似度、置信度等指标作为评分标准,使得用户相似度的计算更加准确、有区分度。然后根据用户属性来衡量用户之间的相似度,利用MovieLens数据集和Book-Crossing数据集做对比实验,对比精度、通用性和不同稀疏度及冷启动情况下的性能。实验结果表明,本文算法不仅提高了推荐精度,而且明显优于其他协同过滤推荐算法,具有更高的实际应用价值。
推荐系统 协同过滤 相似性度量 稀疏性问题
0 引 言
近十年,电子商务得到长足的发展,商户之间的竞争也逐步需要商户本身主动去掌握更准确的用户的需求和偏好,从而有针对性地为客户提供服务者。因此一种高准确定、高性能的推荐过滤算法显得十分重要[1]。协同过滤推荐可以充分利用信息间的联系,执行效率高,可以得到较好的推荐结果,因而成为当前研究的热点[2]。
针对协同过滤推荐问题,国内外学者和专家进行了大量深入的研究。迄今为止,协同过滤推荐算法众多[3-6],每一种协同过滤推荐算法的工作思想不同,在实际应用,这些协同过滤推荐算法均存在各自的优势,同时缺陷也十分明显:如数据稀疏、冷启动、可扩展性差等[7-9]。为了解决这些不足,一些学者提出了采用关联规则数据挖掘、贝叶斯网络、神经网络、支持向量机等技术[10-12],以提高推荐系统的推荐精度,获得了不错的推荐效果。然而用户兴趣受到多种因素的综合作用和影响,当前协同过滤推荐算法的相似度值计算不科学,缺乏合理性,忽略了用户的兴趣信息,推荐精度有待进一步提高[13]。
为了提高协同过滤推荐系统的推荐效率和准确性,设计了一种基于用户评分和属性相似度相融合的协同过滤推荐算法。利用MovieLens数据集和Book-Crossing数据集做对比实验,对比精度、通用性和不同稀疏度及冷启动情况下的性能。
1 经典协同过滤推荐算法
1.1 经典协同过滤推荐算法
经典协同过滤推荐算法工作过程如下:
(1) 建立用户对项目评价的评分矩阵R={rij}m×n,其中,m、n分别表示用户数和项目数,rij为用户i对项目j的评分,其可以描述用户的判断和偏好,具体如表1所示。
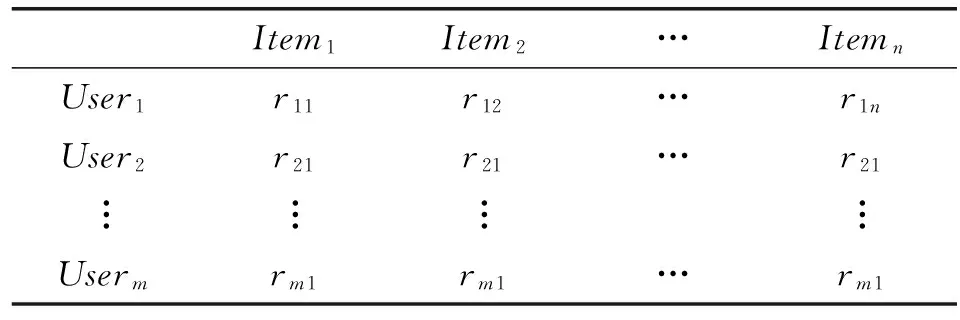
表1 用户-项目评分矩阵
(2) 根据评分值得到用户的相似度值,然后对相似度值进行排序,从中选择k个近邻。
(3) 根据k个近邻对用户与项目评分值进行估计。设i的“最近邻居”集为Si,i对项目x的评分值为Pix,那么有:
(1)
1.2 传统相似度计算方法
传统相似度计算方法主要有:余弦相似度、相关相似度。
(1) 余弦相似度:用户评分为一个向量,当用户不对具体项目进行评分时,那么就认为该评分值等于0,用户i和j间的相似度sim(i,j)计算公式为:
(2)
其中:rix、rjx分别为用户i和j对项目x的评分值。
(2)Pearson相似度:Pearson相似度只考虑两个用户共同评分的项目集合,去掉全部评分的平均值。两个用户i和j的共同评分为Iij(Iij=Ii∩Ij),Pearson相似度计算公式为:
(3)
2 协同过滤推荐算法
经典算法存在相似度值计算不科学,缺乏合理性,忽略了用户的兴趣信息等缺陷,导致推荐误差大,推荐结果不可靠[14]。为提高推荐精度,挖掘用户评分中的兴趣信息,本文提出了一种新的相似度计算方法。
2.1 用户评分相似度
用户评分相似度可以描述两个用户对同一项目评分的非线性变化趋势,为此,引入非线性函数描述用户评分相似度,那么两个用户对同一项目评分的相似度计算公式为:
(4)
2.2 兴趣的倾向相似度
每个用户有自己的评分习惯,对一个具体项目,有的用户给高分,然而有的用户却给低分,这样用户的平均评分描述了用户对某目标的兴趣,用户i和j对同一个项目兴趣倾向相似度计算公式为:
(5)
2.3 用户评分相似度的置信度
当两个用户对某一个项目给出相近的分数时,但是也不完全表示两个用户是相似的,因为相似度还有一个置信度,为此选择Jaccard函数度量置信度,具体计算公式为:
(6)
其中,Ii表示用户i评价的项目集合。综上所述,相似度最终计算公式为:
sim3(i,j)
(7)
2.4 用户属性相似度
经典协同过滤推荐算法仅通过已有用户相关信息实现推荐,无法对新用户信息进行精确评价,导致产生冷启动的概率十分高。在用户评分数目不多时,通过用户属性相似度进行推荐,随着用户评分项目的增多,通过用户评分来进行推荐。为此,引入sigmoid函数将用户属性推荐和用户评分推荐进行融合,实现两者的平滑过渡。设用户i的特征向量为Attri=(ai1,ai2,…,ain),n是用户属性的个数,如果用户i和j的第m个属性相同,simAttr(i,j,m)=1,不然simAttr(i,j,m)=0,这样用户i和j属性的相似度计算公式为:
simAttr(i,j)=∑m∈Attrwm·simAttr(i,j,m)
(8)
其中,wi是第i个属性的权值。
2.5 用户属性相似度与用户评分相似度融合
用户属性相似度与用户评分相似度融合的计算公式为:
sim(i,j)=α·simAttr(i,j)+β·simscore(i,j)
(9)
(10)
β+α=1
(11)
2.6 本文算法的工作步骤
Step1 收集用户的属性维度和对应数据值,同时建立属性矩阵。
Step2 收集用户的属性评分数据及对应的值,同时计算评分的值,建立相似度评分矩阵。
Step3 对两种矩阵进行分析,综合两者可以得到用户相似度矩阵。
Step4 通过相似度矩阵得到用户i的K个近邻,通过式(12)估计未评分项目x的值,并根据结果得到相应的推荐方案。
(12)
其中,NK是与用户最相似的K个邻居;rki是用户k对x的评分。
3 仿真实验
3.1 数据集
在Intel(R)Corei5-3337U3.0GHzCPU,4GBRAM,WindowsXP操作系统计算机上,采用VisualC++编程进行仿真测试。数据来自公开数据集MovieLens,其描述具体见文献[11]。
3.2 对比算法及评价标准
为了使本文算法实验结果更具说服力,选择文献[15]、文献[16]的协同过滤推荐算法进行对比实验,选择平均绝对误差(MAE)作为算法性能优劣的评价标准,其定义如下:
(13)
式中,N为测试集大小,pi为推荐算法的预测评分值,qi为用户的实际评分值。
3.3 结果与分析
推荐精度比较 最近邻数为35时,采用推荐算法对问题进行求解,具体结果图1所示。从图1可以清楚看出,本文协同过滤推荐算法的MAE值低于对比算法,有效提高了推荐的精度,获得了比较理想的推荐结果。
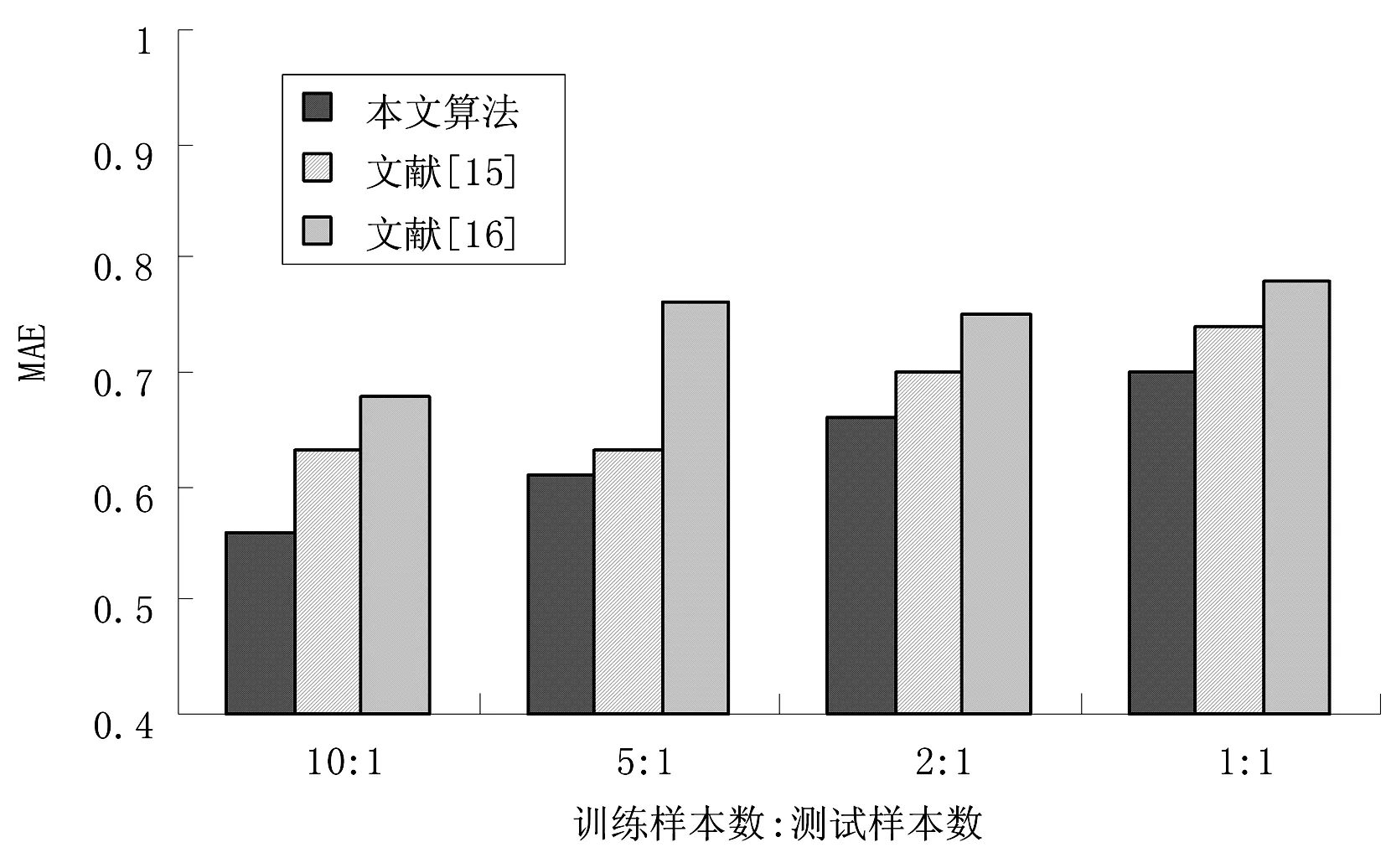
图1 不同算法的推荐精度对比
冷启动条件下的结果分析 为了模拟冷启动条件,选择10个用户,并删除其评价信息,结果如图2所示。对图2进行详细分析可知,本文融合用户评分和属性相似度的协同过滤推荐算法能解决当前存在的冷启动情况下推荐算法无法施行的难题,提高了推荐精度,获得更优的推荐结果。
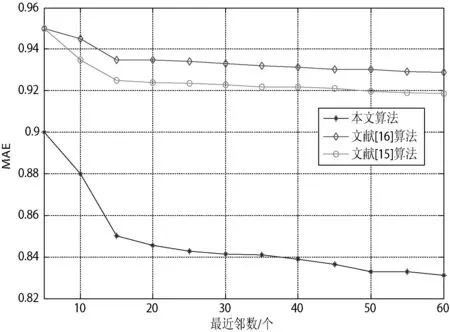
图2 冷启动条件下的算法性能对比
不同稀疏度下的性能对比 不同数据稀疏度的推荐误差如图3所示。数据稀疏度与MAE之间是一种近似线性变化关系,但是在同等条件下,与文献[15]和文献[16]的对比结果发现本文算法推荐结果的MAE值更小。因此本文算法的推荐精度优于同样条件下的文献[15]和文献[16]的算法。
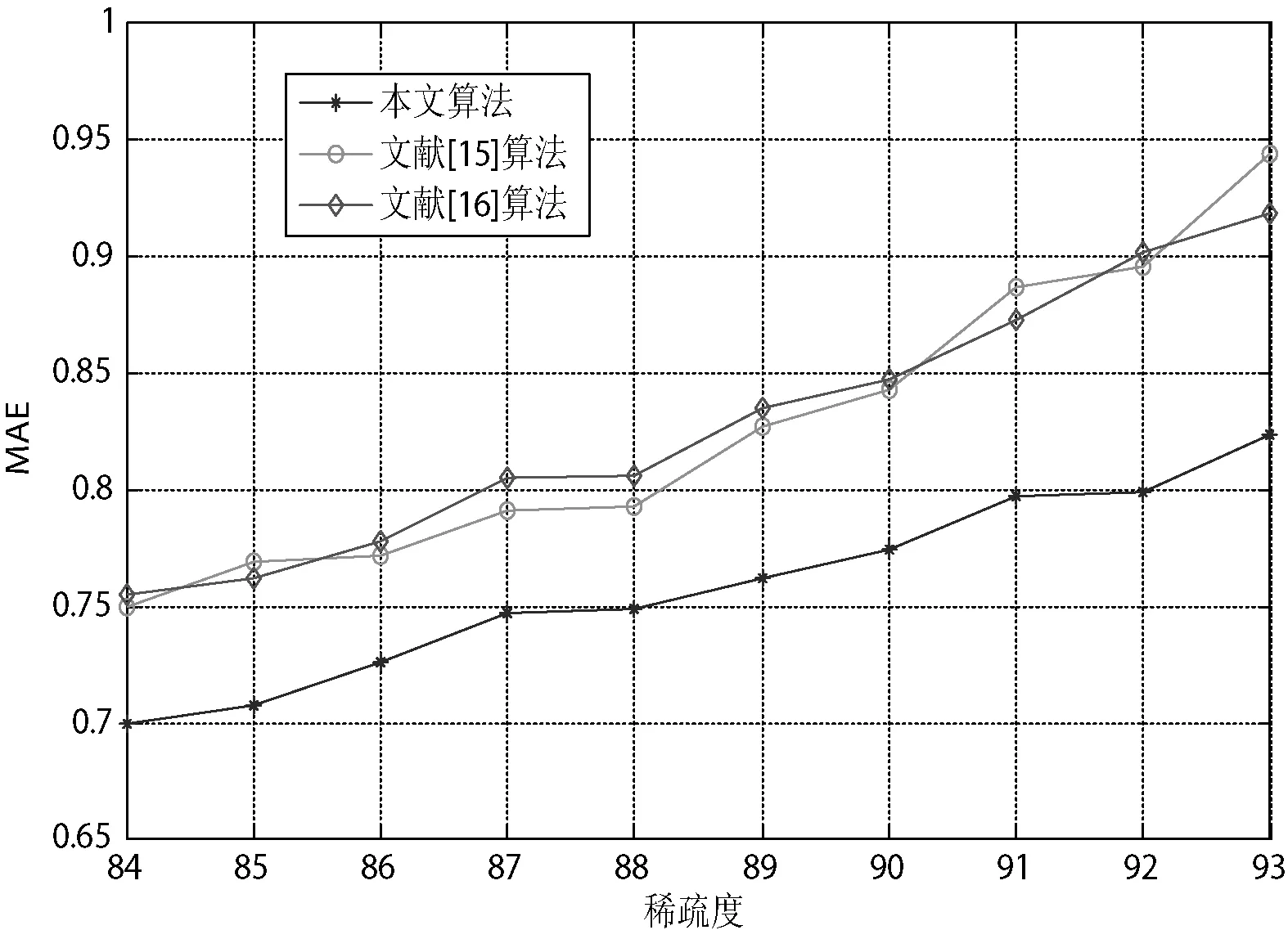
图3 稀疏度不同情况下三种算法的性能对比
通用性测试 为了验证本文融合用户评分和属性相似度的协同过滤推荐算法的通用性,选择Book-Crossing数据集进行仿真测试,有287 558个用户信息及他们对231 797本电子书的1 491 807评分数据。我们采取[0,10]区间内数据对评价建模采取评分制,1:评价最高,0:评价最低。不同算法的实验结果如图4所示。从图4可知,相对于其他协同过滤推荐算法,本文协同过滤推荐算法的MAE也最小,推荐精度更高,再次证明了本文算法的优越性以及良好的通用性。
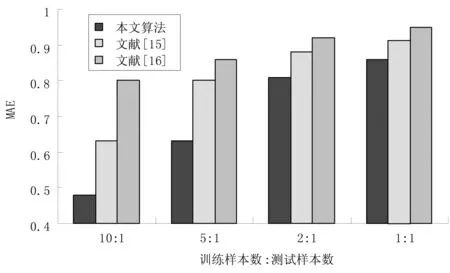
图4 与经典算法的性能对比
4 结 语
过滤推荐系统一直是电子商务研究中的重点和热点,为了得到高准确度、高性能、通用性和适应性更强的推荐结果,本文设计了一种融合用户相似度和评分属性的协同过滤推荐算法。首先收集用户的属性维度和对应的值,再收集描述用户对项目的兴趣信息的评分信息,以增强用户相似度的区分度。然后采用用户属性来衡量用户之间的相似度,最后采用多个数据集进行仿真测试。仿真实验结果表明,本文方法利用了用户依靠,能够大幅度提高推荐质量,推荐可以满足用户实际要求,具有一定的实际应用价值。
[1]MichaelJ,AndreasT,RobertL.Combiningpredictionsforaccuraterecommendersystems[C]//Proceedingsofthe16thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining,2010:693-702.
[2]CachedaF,CarneiroV,FernA,etal.Comparisonofcollaborativefilteringalgorithms:Limitationsofcurrenttechniquesandproposalsforscalable,high-performancerecommendersystems[J].ACMTransactionsontheWeb,2011,5(1):2-10.
[3]BellogínA,CastellsP,CantadorI.Self-adjustinghybridrecommendersbasedonsocialnetworkanalysis[C]//Proceedingsofthe34thinternationalACMSIGIRconferenceonResearchanddevelopmentinInformationRetrieval,2011:1147-1148.
[4]HeZ.ThestudyofpersonalizedrecommendationbasedonWebdatamining[C]//IEEE,InternationalConferenceonCommunicationSoftwareandNetworks.IEEE,2011:386-390.
[5]DouGQ,ZhuYS,HanYM.ResearchonselectionsystembasedonBayesianrecommendationmodel[C]//InternationalConferenceonAdvancedMechatronicSystems.IEEE,2011:35-38.
[6]MaiJ,FanY,ShenY.ANeuralNetworks-BasedClusteringCollaborativeFilteringAlgorithminE-CommerceRecommendationSystem[C]//InternationalConferenceonWebInformationSystemsandMining.IEEE,2009:616-619.
[7] 韦素云,业宁,朱健,等.基于项目聚类的全局最近邻的协同过滤算法[J].计算机科学,2012,39(12):149-152.
[8]ChenZhiMin,JiangYi,ZhaoYao.Acollaborativefilteringrecommendationalgorithmbasedonuserinterestchangeandtrustevaluation[J].InternationalJournalofDigitalContentTechnologyanditsApplications,2010,4(9):106-113.
[9]WangMJ,HanJT.Collaborativefilteringrecommendationbasedonitemratingandcharacteristicinformationprediction[C]//InternationalConferenceonConsumerElectronics,CommunicationsandNetworks.IEEE,2012:214-217.
[10]WuYK,TangZH.CollaborativefilteringsystembasedonclassificationandextendedK-meansalgorithm[J].AdvancesinInformationSciencesandServiceSciences,2011,3(7):187-194.
[11]WuYK,YaoJR,TangZH,etal.CollaborativeFilteringBasedonMulti-levelItemCategorySystem[J].JournalofConvergenceInformationTechnology,2012,7(7):64-71.
[12] 李鹏飞,吴为民.基于混合模型推荐算法的优化[J].计算机科学,2014,41(2),68-71.
[13] 孙金刚,艾丽蓉.基于项目属性和云填充的协同过滤推荐算法[J].计算机应用,2012,32(3):658-660,668.
[14] 韦素云,业宁,朱健,等.基于项目聚类的全局最近邻的协同过滤算法[J].计算机科学,2012,39(12):149-152.
[15]QiL,EnhongC,HuiX,etal.EnhancingcollaborativefilteringbyuserinterestexpansionviapersonalizedRanking[J].IEEETransactionsonSystems,Man,andCybernetics,PartB:Cybernetics,2012,42(1):218-233.
[16] 邹永贵,望靖,刘兆宏,等.基于项目之间相似性的兴趣点推荐方法[J].计算机应用研究,2012,29(1):116-118,126.
A COLLABORATIVE FILTERING RECOMMENDATION ALGORITHM BASED ON USER SCORE AND ATTRIBUTE SIMILARITY
Wang Sanhu1Wang Fengjin2
1(DepartmentofComputerScienceandEngineering,LvliangUniversity,Lvliang033000,Shanxi,China)2(TongfangCo.,Ltd,Beijing100083,China)
In order to improve the recommendation efficiency and accuracy of collaborative filtering recommendation system, and to provide personalized recommendation service, a recommendation algorithm based on user score and attribute similarity is proposed. Firstly, the current status of collaborative filtering recommendation research is analyzed, and the similarity, similarity of interest tendency, confidence and other indicators are used as the scoring criteria, which makes the calculation of user similarity more accurate and discriminative. Then the similarity between users is measured according to the attributes of the users. The comparison is made between the MovieLens data set and the Book-Crossing data set, and the accuracy, versatility and performance under different sparsity and cold start conditions are compared. Experimental results show that the proposed algorithm not only improves the recommendation accuracy, but also is superior to other collaborative filtering recommendation algorithms, and has higher practical application value.
Recommendation system Collaborative filtering Similarity measurement Sparsity problem
2016-11-09。山西省教育厅教学改革项目(J2014120,J2015121)。王三虎,副教授,主研领域:数据库应用技术,算法设计,数据挖掘。王丰锦,高工。
TP3
A
10.3969/j.issn.1000-386x.2017.04.052
猜你喜欢
防爆电机(2022年4期)2022-08-17 05:59:50
重庆大学学报(2022年6期)2022-06-23 07:32:50
客联(2021年2期)2021-09-10 07:22:44
中国眼镜科技杂志(2019年9期)2019-11-11 12:15:26
电子制作(2018年11期)2018-08-04 03:25:38
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
军事体育学报(2014年4期)2014-02-27 16:00:47
河南科技(2014年14期)2014-02-27 14:11:53
城市道桥与防洪(2014年5期)2014-02-27 07:26:16
